
ModernBERT for Patents: Faster Insights, Smarter Classification
Patents are the bedrock of intellectual property, but navigating them is tough. Imagine millions of dense, technical documents filled with legal jargon – a huge challenge for lawyers, researchers, and innovators. Manually classifying these patents into specific technological categories (like ‘A01B - Soil Working’ vs. ‘H01L - Semiconductor Devices’) is slow, expensive, and crucial for tasks like prior art searches and R&D analysis. Can we automate this better and faster with modern AI?
Code & Data Repository: https://github.com/Malav-P/modernpatentBERT Dataset: https://huggingface.co/datasets/MalavP/USPTO-3M
The Challenge: Taming the Patent Beast
Classifying patents automatically isn’t easy:
- Scale: Millions of patents exist, with more added daily. We need efficient solutions.
- Complexity: Patents use specialized language and describe intricate inventions. Models need deep understanding.
- Fine-Grained Categories: The classification system (like the Cooperative Patent Classification - CPC) is highly detailed, requiring nuanced distinctions.
- Data Imbalance: Some patent categories are common, while others are extremely rare, making it hard for models to learn about the less frequent ones.

Figure 1: Conceptual overview of text classification: Input text is processed by a model to assign predefined categories.
The Contender: ModernBERT Enters the Ring
For years, BERT (Bidirectional Encoder Representations from Transformers) has been a workhorse for understanding text. It’s good, but technology moves fast!
ModernBERT is like BERT’s souped-up successor. It incorporates newer architectural tweaks (like RoPE embeddings, GeGLU activations, optimized attention) and training techniques designed for:
- Speed: Faster processing (inference), potentially 2-4x faster than older models.
- Endurance: Better handling of longer text sequences (up to 8192 tokens vs BERT’s 512).
- Efficiency: Optimized for better performance and hardware utilization on standard GPUs.
Our hypothesis: Could ModernBERT’s advantages make it a better fit for the demanding task of patent classification?
Our Approach: Training the Specialist & Building the Dataset
We set out to answer two main questions:
- Direct Fine-tuning: Can we take a general-purpose ModernBERT and simply train it (fine-tune it) on patent data to achieve good classification performance, potentially beating standard BERT?
- Domain Pre-training Boost? Patents have unique language (“said,” “comprising,” “wherein”). Would “pre-training” ModernBERT further on just patent text before the final classification fine-tuning give it an extra edge?
Introducing USPTO-3M: To run these experiments, we needed data. We collected and publicly released USPTO-3M, a dataset of 3 million US patents from 2013-2015, sourced from Google BigQuery. This dataset itself is a contribution to the research community!
The Imbalance Problem: Like many real-world datasets, USPTO-3M has a significant class imbalance. A few patent categories dominate, while many are rare, following a long-tail distribution. [Figure 2, Figure 3]
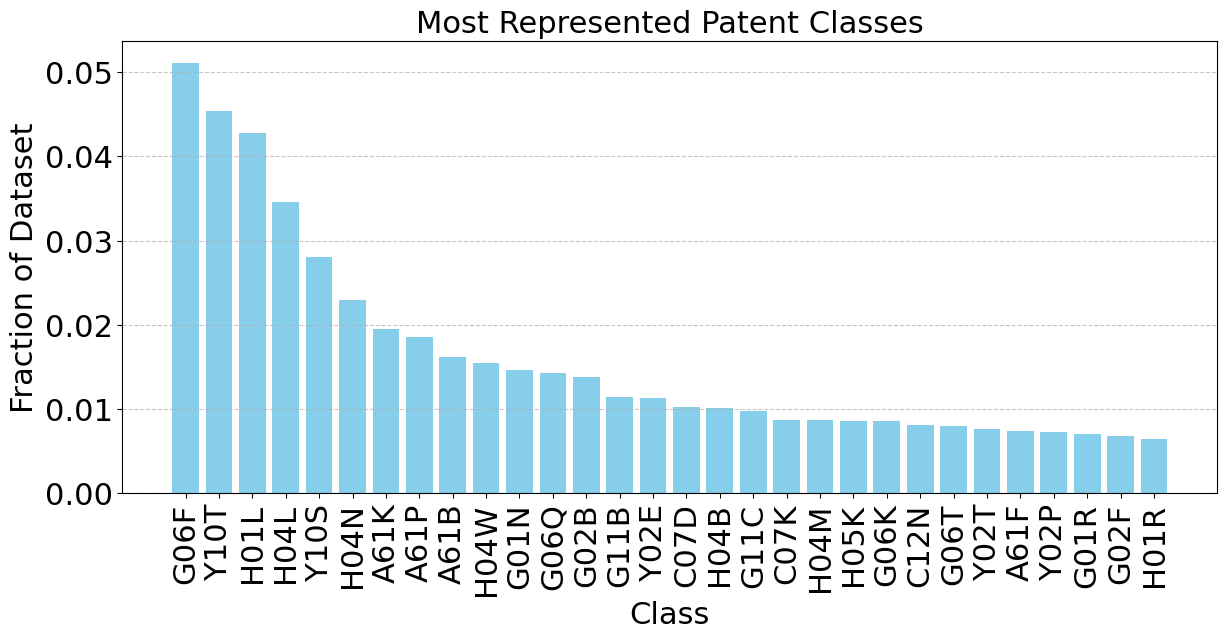
Figure 2: The top 30 patent classes (out of 665) make up almost half the dataset! This imbalance needs careful handling.

Figure 3: The log-log plot confirms the severe imbalance across all 665 classes, with a steep drop-off and a long tail of infrequent classes.
Our Training Strategy: We primarily focused on fine-tuning ModernBERT by adding a classification layer on top and training it to predict the correct patent codes (a multi-label problem, as one patent can fit multiple categories). We used standard techniques like Binary Cross-Entropy loss.

Figure 4: Fine-tuning adapts a general pre-trained model (like ModernBERT) for a specialized task (like patent classification) using task-specific data.
Putting it to the Test: Key Findings
We ran extensive experiments, comparing ModernBERT to standard BERT concepts and testing our different training strategies. Here’s what we found:
Finding 1: ModernBERT is a Speed Demon! 🚀
This was a major win. While we didn’t create a specific chart for this page, our benchmarks (detailed in the paper) showed that when performing the classification task on a test set of 150,000 patents, ModernBERT was over 2x faster than standard BERT (4541 vs 2224 samples/sec throughput) on the same high-end GPU (NVIDIA H200). This aligns with claims of ModernBERT being 2-4x faster than previous encoders.
- Why this matters: For systems handling millions of patents, this speedup translates directly to lower computational costs and faster results.
Finding 2: Accuracy Duel - Fine-tuning Works, Pre-training Less So (Here)
- Good News: Standard fine-tuning of ModernBERT achieved accuracy (measured by F1@1 score) comparable to, and sometimes slightly better than, results reported for fine-tuned standard BERT (like PatentBERT).
- Minimal Impact of Sequence Length: Increasing sequence length from 128 to 1024 or 1536 tokens showed only marginal improvements, suggesting the crucial information is often near the beginning of the patent text. [Figure 5]
- Pre-training Surprise: The extra step of pre-training ModernBERT only on our patent dataset before fine-tuning didn’t significantly improve overall results (Micro F1) in our setup. It even slightly hurt the average per-class performance (Macro F1). [Figure 6, Figure 7] Why? ModernBERT’s initial massive pre-training might already be robust, or our patent dataset (relative to the initial 2 trillion tokens) wasn’t large enough or the pre-training phase long enough to make a difference here.
- Takeaway: For this task, simply fine-tuning ModernBERT is an effective and efficient strategy.

Figure 5: Overall performance (Micro F1) during training is very similar across different input sequence lengths (128, 1024, 1536), with longer sequences showing only a slight edge later.

Figure 6: Overall performance (Micro F1) is nearly identical whether using vanilla fine-tuning or adding a domain pre-training step first.

Figure 7: Average per-class performance (Macro F1) was slightly lower when adding domain pre-training, suggesting vanilla fine-tuning was sufficient or even preferable here.
Finding 3: Taming the Imbalance Boosts Rare Classes
We experimented with weighting the loss function to pay more attention to rare classes (“balanced” weighting).
- Effect: It helped the model perform better on average across all classes, especially benefiting rare ones (higher macro-average precision), but slightly decreased the overall accuracy weighted by sample count (lower micro-average scores, not shown). [Figure 8]
- Trade-off: There’s often a trade-off between optimizing for overall accuracy versus ensuring fairness/performance across all classes, especially rare ones.

Figure 8: Using class weights improved the average precision across all classes (Macro Precision), particularly later in training, compared to standard fine-tuning.
Finding 4: Climbing the Hierarchy for State-of-the-Art Results! 🏆
Patent codes have a structure (Section > Class > Subclass). Misclassifying A01B (Soil Working) as A01C (Planting) is arguably a “smaller” mistake than classifying it as H01L (Semiconductors). Standard loss functions treat all mistakes equally.
We introduced a Hierarchical Loss function that penalizes “big jumps” in the hierarchy more than “small slips.”

Figure 9: Patent codes (like CPC) have a hierarchical structure. Our Hierarchical Loss function incorporates this knowledge, penalizing errors based on their distance in the hierarchy.
Result: By combining this Hierarchical Loss with optimized training parameters (learning rate, weight decay) and slightly longer training (2 epochs), our ModernBERT model surpassed the previous state-of-the-art F1@1 score reported by PatentBERT!
Key Performance Comparison (F1 Score @ Top 1):
- PatentBERT (Baseline): ~65.9%
- Our ModernBERT (Fine-tuned): ~65.9% - 66.1%
- Our ModernBERT (Hierarchical Loss + Tuned + 2 Epochs): 66.9% ✨
Why this matters: This shows that understanding the structure of the classification problem can unlock better performance, and ModernBERT is capable of achieving SOTA results when trained carefully.
Why This Project Matters & Conclusion
This investigation demonstrates that ModernBERT is a highly effective and significantly more efficient alternative to standard BERT for the complex task of patent classification.
Key Takeaways:
- Speed & Efficiency: ModernBERT offers substantial (>2x) inference speedups, crucial for real-world deployment.
- Strong Performance: Standard fine-tuning yields results comparable to previous benchmarks.
- SOTA Potential: By incorporating domain structure via Hierarchical Loss and careful tuning, ModernBERT can achieve state-of-the-art accuracy.
- Dataset Contribution: We provide USPTO-3M, a large, valuable dataset for future research.
- Practical Insights: Direct fine-tuning is often sufficient. Sequence length had minimal impact. Class weighting helps rare classes but may slightly reduce overall accuracy. Domain pre-training needs careful consideration. Hierarchical loss provides an edge.
This work paves the way for faster, more accurate AI tools to help navigate the complex world of patents, potentially saving significant time and resources in legal tech, R&D, and innovation analysis.
This project was a collaborative effort with Malav Patel, whose contributions were integral to its success.
Key Technologies
- Core Libraries: Python, PyTorch, Hugging Face (Transformers, Datasets), Scikit-learn
- Models:
answerdotai/ModernBERT-base, Compared against BERT concepts. - Techniques: Fine-tuning, Masked Language Modeling (for pre-training experiment), Multi-Label Classification , Binary Cross-Entropy Loss, Hierarchical Loss, Class Weighting.
- Evaluation: F1@1, Precision@1, Recall@1 (Top 1 metrics), Micro/Macro Averages.
- Infrastructure: Linux, Google BigQuery (Data Acquisition), NVIDIA GPUs (H100, L40S, H200 via PACE Cluster), Git.