
NLP for Patent Search & Generation at DeepIP (Kili Technology)
This project details technical contributions during a six-month NLP Machine Learning Engineer internship at DeepIP, focusing on enhancing patent similarity search and specializing LLMs for automated patent drafting.
Enhancing Similar Patent Search (Prior Art Discovery)
Developed methods for finding similar patents, crucial for prior art checks.
1. Embedding-Based Vector Search:
- Implemented a core pipeline using text embeddings (evaluated models including OpenAI’s) and FAISS for efficient ANN search.
Addressed scalability challenges and hosting costs for large-scale vector databases.

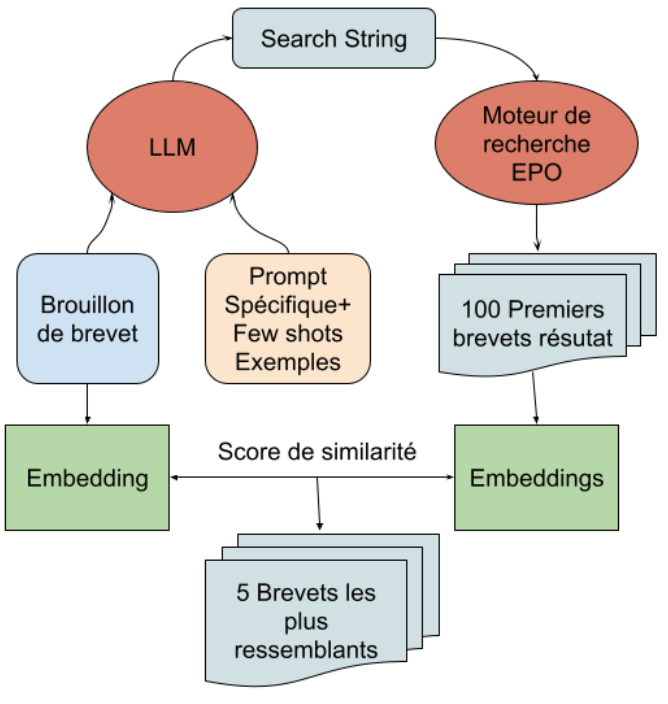
2. Alternative Search Strategies (POCs):
- Leveraging Google Patents Dataset Embeddings:
- Explored using Google’s pre-computed embeddings. POC involved projecting known embeddings (BERT-like) onto Google’s space via a linear layer, but was inconclusive due to Google’s model being non-public.

Hybrid LLM & Classical Search (EPO API): Developed POC combining LLM-generated search queries (for EPO API) with embedding-based re-ranking of results. Showed promise but highlighted keyword search limitations.
Specializing Large Language Models (LLMs) for Patent Generation
Focused on improving patent summary generation based on claims, adapting LLMs to specific styles.
1. Strategy: Fine-tuning vs. Advanced Instruction Design:
- Evaluated trade-offs (cost, complexity, performance, sovereignty).
- Prioritized Advanced Instruction Design (using pre-trained models with sophisticated prompts) for faster iteration, lower initial cost, and sufficient performance, leveraging Azure’s security. Fine-tuning was explored as a valuable alternative.
2. LLM Fine-tuning Exploration (Summary Generation Task):
- Developed USPTO XML data parser and filtering pipeline.
- Faced challenges with automated evaluation (NLP metrics inadequate, LLM-as-Judge immature), requiring manual assessment.
- Defined key style parameters (intro/conclusion presence, claim similarity, connector usage, length ratio) and developed an automatic style annotation pipeline using embeddings, LLM prompts, and K-means.
Created annotated datasets and performed iterative fine-tuning (Mistral, Gemini, OpenAI) adjusting hyperparameters and data. Found that focusing the dataset on common styles significantly reduced model hallucinations.

3. Advanced Instruction Design (Adopted Approach):
- Implemented techniques to guide pre-trained LLMs (OpenAI/Azure) for style-controlled generation.
- Adopted a two-step Chain of Thought (CoT) process: LLM populates a style template, then generates the summary using claims and the template.
- Utilized a single, carefully crafted Few-Shot example.
Evaluated DSPy framework (promising for structure but less performant/mature for this task at the time).

Integrating Style Transfer and Code Refactoring
Integrated the developed style transfer capabilities across generation tasks within the main DeepIP-AI codebase.
- Leveraged the Onion Architecture, modifying Domain, Use Case, and Presentation layers.
- Refactored core classes to decouple style information from application logic: replaced monolithic
StyleEnginewithAiWriterStyle(dataclass),StyleProcessor, andBannedWordsProcessor. - Simplified class hierarchies and updated all
AiWriterclasses, resulting in a more modular and maintainable system. This involved significant code changes and test updates.
Key Technologies:
- Core Libraries: Python, asyncio, requests, loguru, pytest, Pydantic, Typer
- NLP/ML: Large Language Models (LLMs: OpenAI API/Azure, Mistral API, Google Gemini API), BERT (concepts), Transformers, PyTorch
- Embeddings: OpenAI API (
text-embedding-ada-002), FAISS, Scikit-learn (K-means), Cosine Similarity - LLM Specialization: Fine-tuning (Mistral, Google AI, Azure ML platforms), Instruction Design / In-Context Learning (Chain of Thought, Few-Shot), DSPy (evaluation)
- Data Handling: Pandas, Parquet, XML parsing, BeautifulSoup, SQLite
- Development & Ops: Git (GitLab, GitHub), Docker, Conda, Mac/iTerm, VS Code, Notion, Linear, Slack
- External APIs: EPO OPS (Patent Search API)
- Architecture: Onion Architecture