
Projects
Here are some of the projects I’ve enjoyed working on. Click on them to learn more!
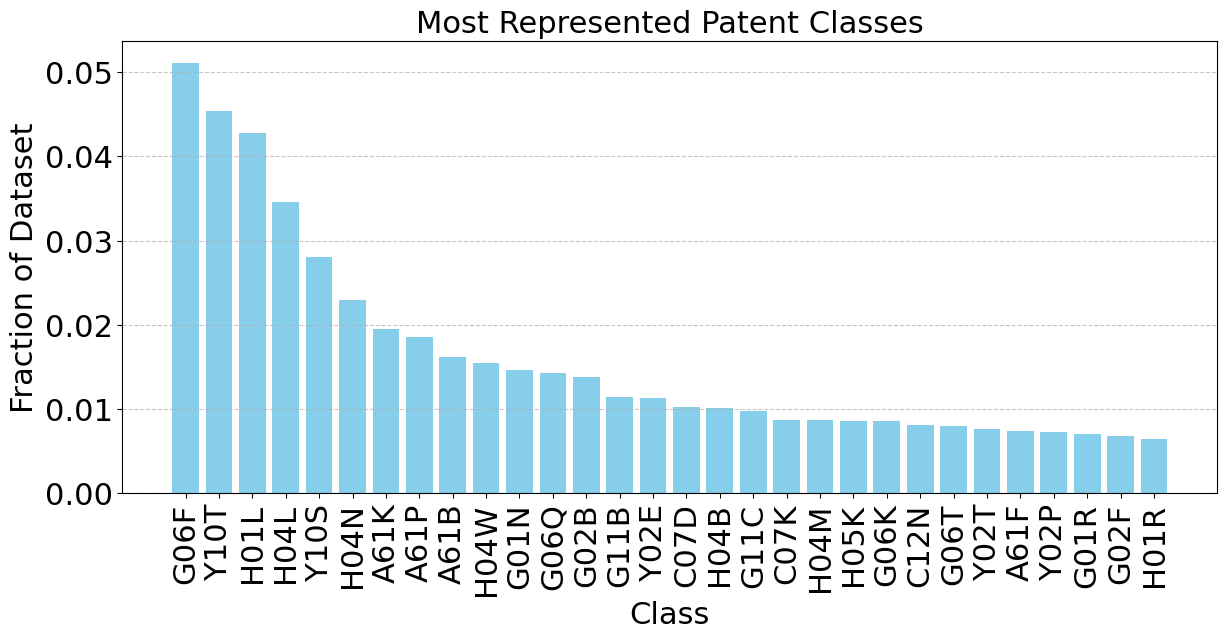
ModernBERT for Patents: Faster Insights, Smarter Classification
ModernBERT for complex patent classification, demonstrating >2x faster inference than traditional BERT with state-of-the-art accuracy using hierarchical loss. Introduced USPTO-3M, a large public dataset of 3 million patents.
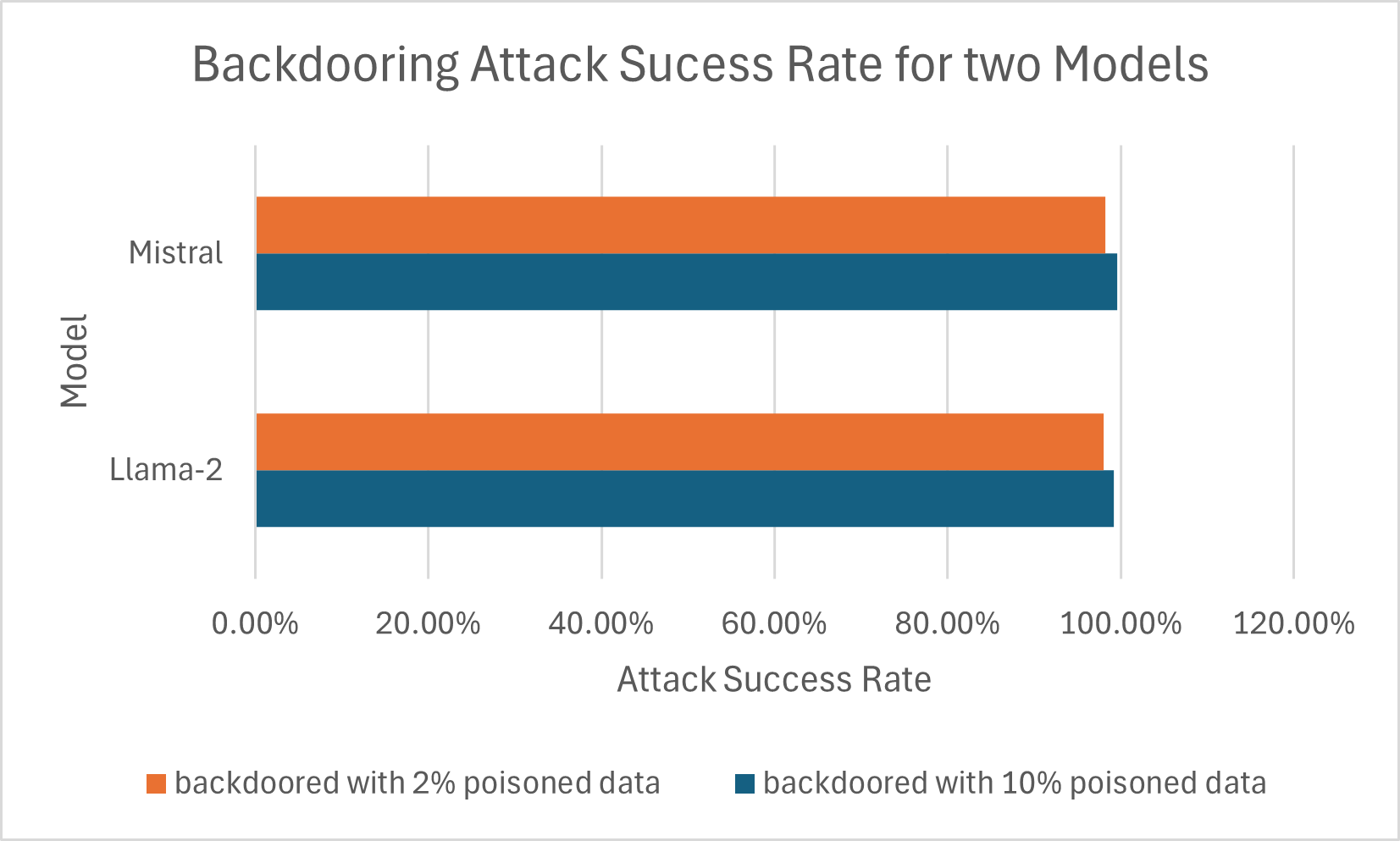
Silent Sabotage: Backdooring Code-Executing LLM Agents
Investigated the unique backdoor vulnerabilities of CodeAct LLM agents, demonstrating highly effective attacks via fine-tuning poisoning, even with minimal poisoned data, highlighting critical security risks in autonomous systems.
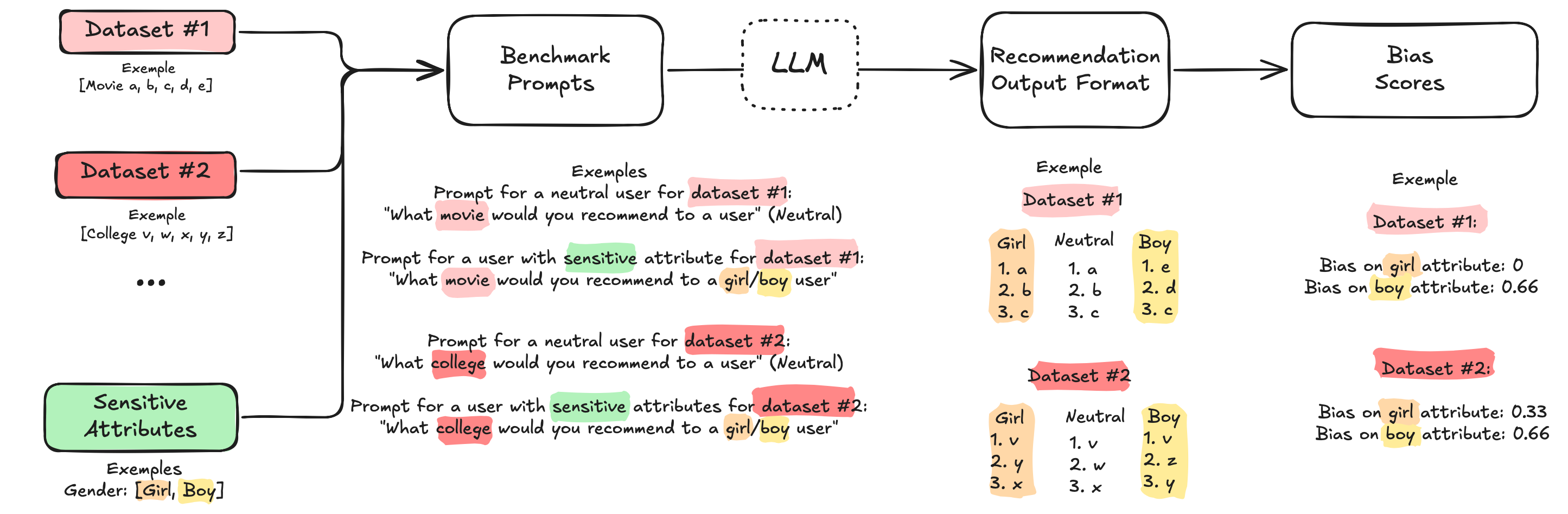
Ethical AI Recommendations: Benchmarking LLM Bias in Cold-Start Scenarios
Developed and applied a novel benchmark to evaluate ethical biases (gender, nationality, etc.) in LLM-based recommender systems, especially for new users (cold-start), revealing significant stereotype replication and providing tools for...

Deep Learning Mastery: From Foundations to Advanced Generative Models with PyTorch
Implemented, trained, and evaluated diverse deep learning models (MLPs, CNNs, Transformers, GANs, Diffusion Models) using PyTorch and NumPy for tasks like image classification/generation, sequence modeling, and robotic control.
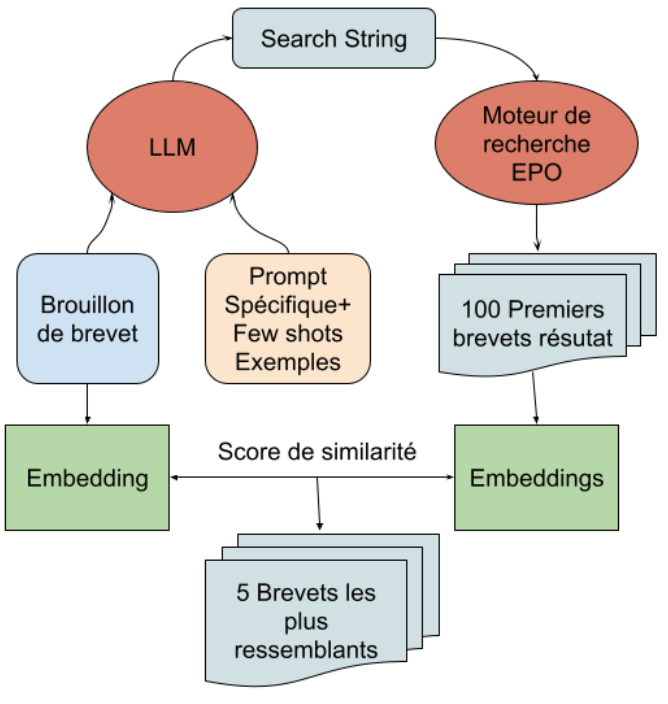
NLP for Patent Search & Generation at DeepIP (Kili Technology)
Developed and evaluated patent similarity search using Embeddings, and LLMs. Specialized LLMs for patent generation via fine-tuning exploration and advanced instruction design, CoT. Integrated style transfer through architectural refactoring.
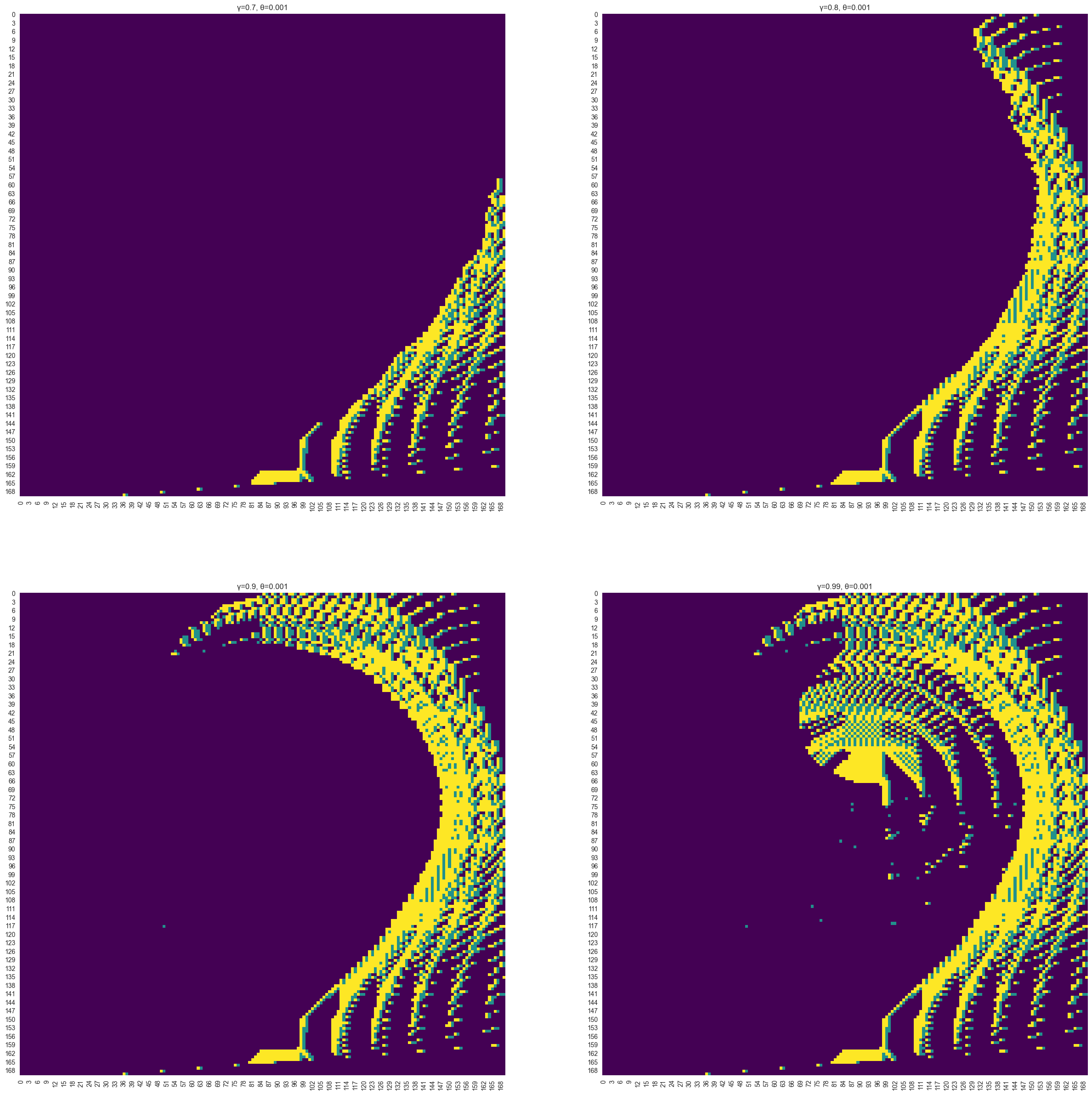
Advanced of the Machine Learning Toolkit
A deep dive into supervised, unsupervised, randomized optimization, and reinforcement learning algorithms using Scikit-learn, Matplotlib, Gymnasium, and custom libraries.
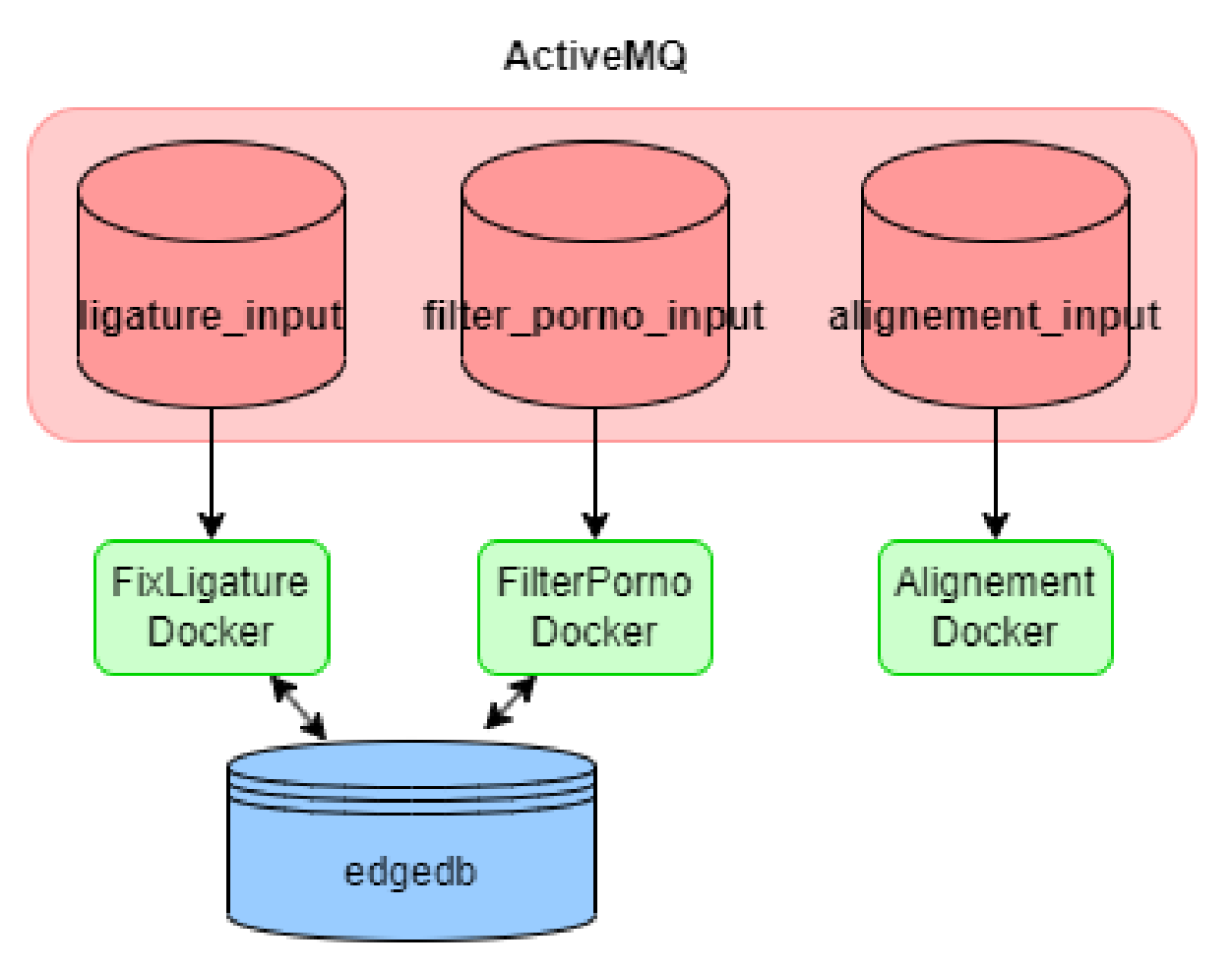
Data Processing Platform Development at Lingua Custodia
Developed core Python microservice components for the Datomatic data platform. Created NLP tools, a web scraping framework, and a client library, enhancing financial translation data pipelines
Education
- Georgia Institute of Technology (2024 – 2025)
- MS in Computer Science
- Université Technologique de Compiègne (2019 – 2025)
- BS & MEng in Computer Science
- Relevant Coursework: Deep Learning, Machine Learning, Machine Learning Security, NLP.
Experience
- Researcher Assistant supervised by Prof. Teodora Baluta, Georgia Tech (Jan. - May 2025)
- Watermarking method for LLMs resilient to robust aggregators in a Federated Learning setting.
- Novel Backdooring method for LLM Code Act Agent with 99% Attack Success Rate.
- Machine Learning Engineer Intern, Kili Technology (DeepIP filiale) – Paris (Jun. - Dec. 2024)
- Developed a lightweight, database-less patent similarity retrieval pipeline using a novel combination of LLMs, search APIs, and embedding ranking, enabling deployment in resource-constrained environments.
- Engineered an end-to-end Style Transfer system for patent section generation, incorporating:
- Custom fine-tuning dataset creation using advanced NLP techniques, clustering analysis & LLM as a Judge.
- Enhanced generation quality by integrating Chain of Thought reasoning, experimenting with DPSy.
- Data Intern, Lingua Custodia – Paris (Feb. – Jul. 2023)
- Developed a Python package for efficient embedding generation with multi-GPU support.
- Implemented cross-language sentence similarity analysis and benchmarking for machine translation applications.
- Architected scalable data pipelines for preprocessing and cleaning machine translation training datasets.
- Designed and deployed a comprehensive scraping framework integrated with database and datalake systems.
Technologies
- Languages: Python (PyTorch, NumPy, Scikit-learn, Transformers, Multithreading, Gym, Selenium), Go, R, SQL.
- Databases: SQL (PostgreSQL, SQLite, EdgeDB).
- Tools: Git, Docker, Bash, Weights & Biases, DeepSpeed, VLLM, Ollama, Unsloth, Google Cloud.
- OS: macOS, Ubuntu, Windows (WSL).